자료구조 프로그래밍 Lab08) BTree (2-3 Tree) 만들기
Btree에 대해 이야기하기에 앞서 Multiway Search Tree에 대해 알아야 한다.
Multiway search Tree란 기존의 BST에서 데이터를 한 번 가져오기 위해서 접근하는 과정에서 오는 손실을 최소화 하고자 한 노드의 데이터를 여러개를 저장할 수 있도록 degree를 늘인 형태이다.
이때 이, Multiway Search Tree 에서도 마찬가지로 level을 최소화하면 탐색 성능이 더욱 향상할 수 있는데 이를 구현한 것이 Btree 이다. Btree는 Balanced, Boeing, Bayer 의 3가지 의미가 있지만 정확한 이름의 유래는 알려지지 않았다.
이 Btree는 몇가지 조건이 존재한다.
- 루트 노드는 공백이거나 적어도 두개의 자식 노드가 존재한다
- 루트 노드와 외부 노드를 제외한 모든 노드는 적어도 ceil(m/2)개의 자식 노드를 갖는다
- 모든 외부 노드들은 같은 레벨에 존재한다
이 Btree 중에서도 order(차수)가 3인 Btree(2-3 Tree)에 대해서 구현을 해보고자 한다.
삽입의 형태는 다음과 같다.
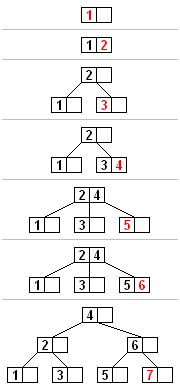
삽입)
1) 해당 위치로 탐색해서 들어간다.
2-1) 만약 해당 노드의 데이터 수가 2개 보다 적다면 해당 위치에 삽입하고 종료
2-2) 만약 해당 노드의 데이터 수가 2개라면 해당위치에 삽입하고 회전처리를 한다.
회전이 이루어진다면 루트노드 까지 가면서 회전 재귀적으로 처리.
삭제)
삭제의 과정은 꽤 복잡하다.
Case 1. 리프 노드 삭제 경우
리프 노드의 삭제일 경우는 단순하다. 삭제 후 개수가 ceil(m/2) 보다 작다면 회전을 처리한다.
아니라면 삭제 후 종료한다. 회전이 이루어진다면 루트노드 까지 가면서 회전 재귀적으로 처리.
Case 2. 내부 노드 삭제 경우
삭제할 원소가 x이고 해당 노드를 n 이라고 한다면 x의 child node 중 원소 수가 t 이상인 child node로 x를 보낸 후 삭제하고 child node가 left 이면 최대값을 right이면 최소값을 n으로 올린다. 올라가면서 계속 회전 체크.
문제

해결
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 | #include <stdio.h> #include <stdlib.h> #define MAX 1000 #define M 3 // 자료형 정의 typedef struct node* nodePointer; typedef struct node { int n; // 가지고 있는 노드 수 int data[M - 1]; // 가질 수 있는 데이터 수 nodePointer p[M]; // subTree }node; nodePointer root = NULL; // Key 상황에 따른 ENUM 형 자료형 enum KeyStatus { InsertFail, SearchFail, Success, InsertIt, LessKeys }; // 전역변수 FILE *fp1, *fp2; int size; // 호출 함수들 void insert(int); void delNode(int); enum KeyStatus ins(nodePointer, int, int*, nodePointer*); int searchPos(int, int *, int ); enum KeyStatus del(nodePointer, int); // 메인 함수 void main(int ac, char* av[]) { int data,choice,key; // argument Error if (ac != 3) { fprintf(stderr, "ARGUMENT ERROR!! use 2 ARGUMENT ex) input.txt output.txt\n"); exit(1); } // FILE OPEN if ((fp1 = fopen(av[1], "r")) == NULL) { fprintf(stderr, "FILE OPEN ERROR!\n"); exit(1); } if ((fp2 = fopen(av[2], "w")) == NULL) { fprintf(stderr, "FILE WRITE ERROR!\n"); exit(1); } // 반복횟수 읽기 fscanf(fp1, "%d ", &size); // 반복 작업 for (int i = 0; i < size; i++) { fscanf(fp1, "%d ", &data); // 데이터 읽기 // 삽입 if (data >= 0) { insert(data); //삽입 처리 } // 삭제 else { data = data * -1; // 부호 변경 delNode(data); } } // 파일 닫기 fclose(fp1); fclose(fp2); } // 삽입 함수 void insert(int key) { nodePointer newnode; int upKey; enum KeyStatus value; // ins를 통해서 해당 값의 상태값 가져온다 value = ins(root, key, &upKey, &newnode); // 이미 있는 값일 경우 경고 발생 if (value == InsertFail) fprintf(fp2, "Key %d 값이 이미 존재합니다!\n", key); // 상태값 inertlt 처리일 경우 if (value == InsertIt) { // 새노드 할당 후 값 넣기 nodePointer uproot = root; root = calloc(1, sizeof(node)); root->n = 1; root->data[0] = upKey; root->p[0] = uproot; root->p[1] = newnode; } } // 삽입 처리(상태 파악) enum KeyStatus ins(nodePointer ptr, int key, int *upKey, nodePointer *newnode) { nodePointer newPtr, lastPtr; int pos, i, n, splitPos; int newKey, lastKey; enum KeyStatus value; // 첫 값일 경우 새로운값 할당 위해 (상태값 초기화 값 반환) if (ptr == NULL) { *newnode = NULL; *upKey = key; return InsertIt; } // 개수 cnt n = ptr->n; // 해당 노드에서 몇번째 인지 위치 찾기 pos = searchPos(key, ptr->data, n); // 해당 위치에 이미 있는 값일 경우 (실패) if (pos < n && key == ptr->data[pos]) return InsertFail; // 자식노드 재귀호출 value = ins(ptr->p[pos], key, &newKey, &newPtr); // 삽입 아닐 경우 단순 반환(탈출용) if (value != InsertIt) return value; // 해당 node의 data 수가 M-1보다 작을 경우 (추가) if (n < M - 1) { // 새 노드의 해당 위치를 가지고 온다 pos = searchPos(newKey, ptr->data, n); // 삽입 추가를 위해 오른쪽으로 한칸씩 이동(data, ptr) for (i = n; i>pos; i--) { ptr->data[i] = ptr->data[i - 1]; ptr->p[i + 1] = ptr->p[i]; } // 해당 위치에 데이터 추가 ptr->data[pos] = newKey; ptr->p[pos + 1] = newPtr; ++ptr->n; // 개수 1개 증가 return Success; // 성공 반환 } // 마지막 값 한자리 남았을 경우 if (pos == M - 1) { lastKey = newKey; lastPtr = newPtr; } // 자리가 다 찼고 위치 마지막 아닐 경우 else { // 중간에 값을 갈라준다(올려줄 값) lastKey = ptr->data[M - 2]; lastPtr = ptr->p[M - 1]; // 값 잘라서 왼쪽 오른쪽 처리 for (i = M - 2; i > pos; i--) { ptr->data[i] = ptr->data[i - 1]; ptr->p[i + 1] = ptr->p[i]; } // 해당 위치에 새로운 값 할당 ptr->data[pos] = newKey; ptr->p[pos + 1] = newPtr; } // 나눠줄 오른쪽 위치 splitPos = (M - 1) / 2; // 올라갈 값(중심값) (*upKey) = ptr->data[splitPos]; // 새노드 할당 (*newnode) = calloc(1,sizeof(node)); // 개수를 잘려진 수로 할당(split) ptr->n = splitPos; // 새노드의 수는 나머지 수 -1 (*newnode)->n = M - 1 - splitPos; // 반복문을 통해 자식 관계 처리 for (i = 0; i < (*newnode)->n; i++) { // 새노드의 자식노드에 기존 ptr의 자식 노드 수 할당 (*newnode)->p[i] = ptr->p[i + splitPos + 1]; // 데이터 옮기기 if (i < (*newnode)->n - 1) (*newnode)->data[i] = ptr->data[i + splitPos + 1]; // 마지막 키 값 넣기 else (*newnode)->data[i] = lastKey; } // 개수값 할당 및 상태값 반환(재귀적으로 계속 체크) (*newnode)->p[(*newnode)->n] = lastPtr; return InsertIt; } // 해당 노드에서 찾는 값의 위치 찾기 int searchPos(int key, int *key_arr, int n) { int pos = 0; while (pos < n && key > key_arr[pos]) pos++; return pos; } // 삭제함수 void delNode(int key) { nodePointer uproot; enum KeyStatus value; // 상태값 처리 value = del(root, key); // 상태값에 따라 // 삭제 실패일 경우 if (value == SearchFail) { fprintf(fp2, "Key %d 값을 찾을 수 없습니다! \n", key); } // 루트 삭제의 경우 else if (value == LessKeys) { uproot = root; // 루트를 옮겨 두고 root = root->p[0]; // 루트는 첫 번째 자식노드를 가지고 free(uproot); // 루트 노드 삭제 } } // 삭제 처리 (상태값 반환) enum KeyStatus del(nodePointer ptr, int key) { int pos, i, pivot, n, min; int *key_arr; enum KeyStatus value; nodePointer *p, lptr, rptr; // 해당 ptr이 NULL이면 삭제실패 if (ptr == NULL) return SearchFail; // 값 할당 n = ptr->n; key_arr = ptr->data; p = ptr->p; // 최소 값은 2번째 값 min = (M - 1) / 2; // 찾을 값 위치 찾기 pos = searchPos(key, key_arr, n); // 만약 해당 노드가 leaf 노드 일 경우 if (p[0] == NULL) { // 위치 n 일 경우 없는 것(삭제 실패) if (pos == n || key < key_arr[pos]) return SearchFail; // 왼쪽으로 한칸씩 땡기기 for (i = pos + 1; i < n; i++) { key_arr[i - 1] = key_arr[i]; p[i] = p[i + 1]; } // 개수 한개 줄이고 값 비교해서 root 값올릴지 비교 // ptr이 root 였다면 1과 개수 비교, ptr이 root가 아니라면 index 2 와 개수 비교 return --ptr->n >= (ptr == root ? 1 : min) ? Success : LessKeys; } // 해당 key 값을 찾았으나 leaf 노드가 아닐경우 - 위치변경 // 위치가 n보다 작고 key 값 맞을 경우 if (pos < n && key == key_arr[pos]) { // qp는 위의 노드 nodePointer qp = p[pos], qp1; int nkey; // 반복문 처리 while (1) { // key 개수값 nkey = qp->n; // 맨 끝 자식 노드 해당값 가져와서 qp1 = qp->p[nkey]; // NULL이면 탈출 if (qp1 == NULL) break; // 값 이동 qp = qp1; } // position 정리 key_arr[pos] = qp->data[nkey - 1]; qp->data[nkey - 1] = key; } // 해당 값 삭제하고 상태값 가져오기 value = del(p[pos], key); // 상태값에 따라서 반환 if (value != LessKeys) return value; // 해당 위치가 있고 개수가 최소 회전위치보다 클 경우 회전 처리 if (pos > 0 && p[pos - 1]->n > min) { // 턴할 위치는 해당 pos -1 pivot = pos - 1; // 왼쪽 ptr lptr = p[pivot]; // 오른쪽 ptr rptr = p[pos]; // 오른쪽 노드에 값 할당 rptr->p[rptr->n + 1] = rptr->p[rptr->n]; // 오른쪽 노드의 자식노드 개수만큼 처리 for (i = rptr->n; i>0; i--) { // data, ptr 옮기기 rptr->data[i] = rptr->data[i - 1]; rptr->p[i] = rptr->p[i - 1]; } // 개수 증가 rptr->n++; // 첫 값은 pivot rptr->data[0] = key_arr[pivot]; // 첫 자식 값은 왼쪽 ptr의 왼쪽 개수 rptr->p[0] = lptr->p[lptr->n]; // key _arr 피벗 돌기에 왼쪽 array값 key_arr[pivot] = lptr->data[--lptr->n]; return Success; } // 만약 최소 (pivot 기준)보다 작을 경우 if (pos < n && p[pos + 1]->n > min) { // pivot에 해당 위치값 넣기 pivot = pos; // 피벗 기준에 따라 위치 지정 lptr = p[pivot]; rptr = p[pivot + 1]; // 왼쪽 ptr 값 할당 lptr->data[lptr->n] = key_arr[pivot]; // 왼쪽 ptr의 개수 처리 lptr->p[lptr->n + 1] = rptr->p[0]; // key_arr 피벗에 첫번째 data 넣기 key_arr[pivot] = rptr->data[0]; // 왼쪽 ptr은 개수 증가 lptr->n++; // 오른쪽 ptr은 개수 감소 rptr->n--; // 오른쪽 노드의 자식노드 개수만큼 처리 (한칸씩 당기기) for (i = 0; i < rptr->n; i++) { rptr->data[i] = rptr->data[i + 1]; rptr->p[i] = rptr->p[i + 1]; } // 오른쪽 ptr의 개수 위치에 오른쪽 ptr 개수 +1 할당 rptr->p[rptr->n] = rptr->p[rptr->n + 1]; return Success; } // 해당 위치가 n 일 경우 if (pos == n) pivot = pos - 1; // 피벗은 pos-1 // 그 외 else pivot = pos; // 피벗은 pos // lptr, rptr - pivot 위치 할당 lptr = p[pivot]; rptr = p[pivot + 1]; // 왼쪽 ptr에다가 오른쪽 값 합쳐주기 lptr->data[lptr->n] = key_arr[pivot]; lptr->p[lptr->n + 1] = rptr->p[0]; // rptr 개수 만큼 왼쪽 ptr의 값에다가 오른쪽 ptr의 값을 할당해주기(나누기) for (i = 0; i < rptr->n; i++) { lptr->data[lptr->n + 1 + i] = rptr->data[i]; lptr->p[lptr->n + 2 + i] = rptr->p[i + 1]; } // 합치고 난 후 오른쪽 ptr 비우기 lptr->n = lptr->n + rptr->n + 1; // 개수 합쳐짐 free(rptr); // array 값 재조정 for (i = pos + 1; i < n; i++) { key_arr[i - 1] = key_arr[i]; p[i] = p[i + 1]; } // 개수 한개 줄이고 값 비교해서 root 값올릴지 비교 // ptr이 root 였다면 1과 개수 비교, ptr이 root가 아니라면 index 2 와 개수 비교 return --ptr->n >= (ptr == root ? 1 : min) ? Success : LessKeys; } | cs |
'Archived(CSE Programming) > 자료구조(C++)' 카테고리의 다른 글
| 우선순위 큐_피보나치 힙(Fibonacci Heap) (0) | 2018.12.09 |
|---|---|
| 자료구조 프로그래밍 Lab09) Patricia 만들기 (0) | 2018.11.30 |
| 자료구조 프로그래밍 Lab07) AVL Tree 만들기 (0) | 2018.11.18 |
| 자료구조 프로그래밍 Lab06) 이항 힙 만들기 (Binomial Heap) (0) | 2018.11.03 |
| 자료구조 프로그래밍 Lab05) 최소 좌향 트리 만들기(Leftist Min Tree, Heap) (0) | 2018.11.03 |


